As I did for COGS 9: Introduction to Data Science in an earlier blogpost, I wanted to quickly take a look at some pre-post survey data from my students in COGS 108 this past Spring.
COGS 108: Data Science In Practice is an upper-level undergraduate data science course. It’s required of cognitive science students but taken by lots of different matjors. Students are expected to have experience programming and the course is intentionally light on exams (read: no exams) and heavy on getting students practice with data science thinking, intuition, and tasks. Assignments are technical and the course is project-based.
This course is quite popular (thanks to Brad Voytek who designed this course and has taught it more than anyone else) and typically very large (N > 300 students). This past quarter was particularly large as we were working to get all caught up with students who needed this course to graduate. I taught two sections of this course with 825 students across both sections last Spring.
Survey Question
Here, I’m going to focus on a single question from two surveys that I sent out to students. Students were given a list of topics – in the first and the last week of the class – and asked the following:
Which of the following topics are you familiar with? (Here, familiar means you could explain the topic clearly to a friend without Googling it first.) Check all that apply.
Pre-Post
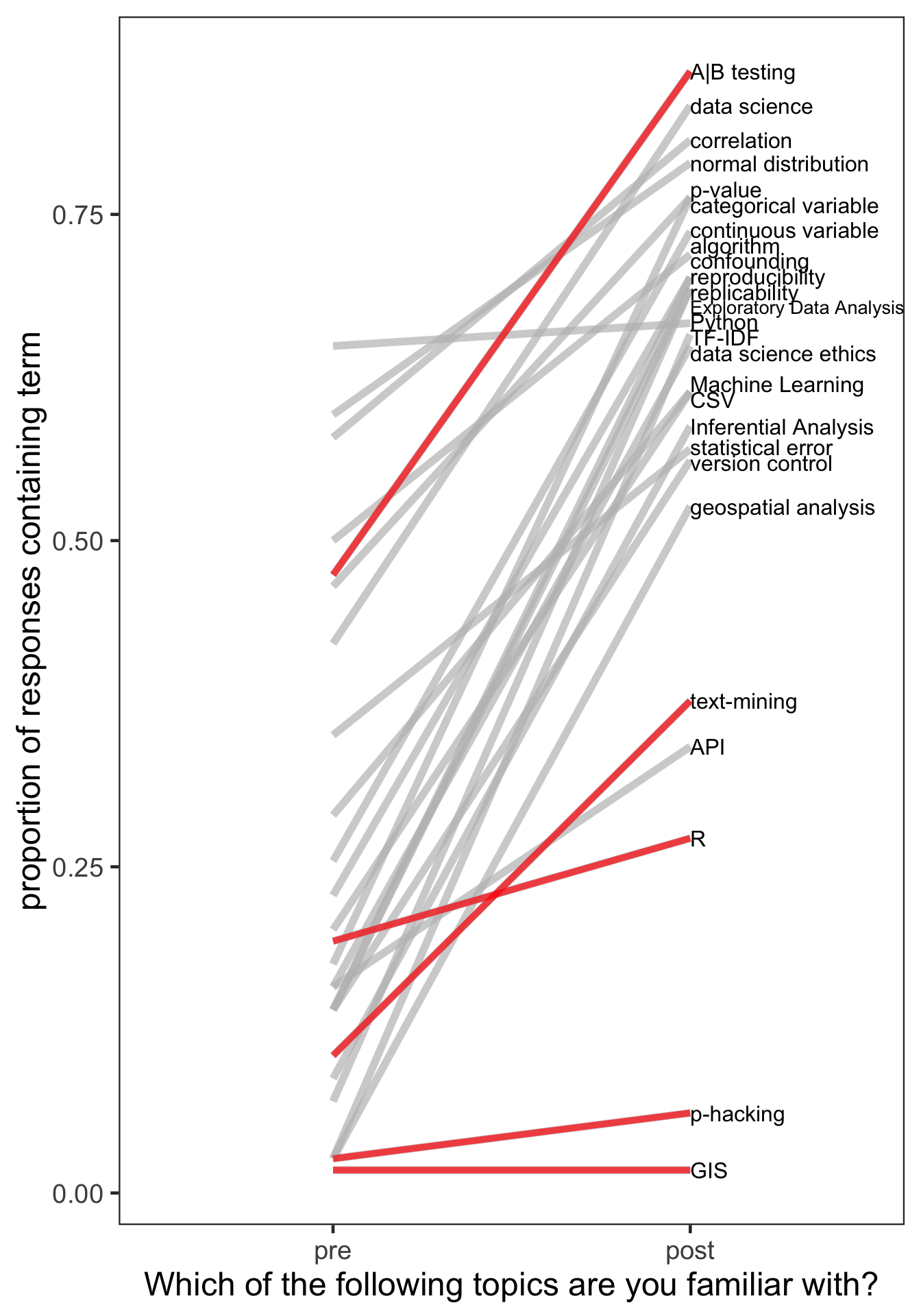
The overall results of this question are summarized here for the 36 students who responded to both the pre- and the post- survey.
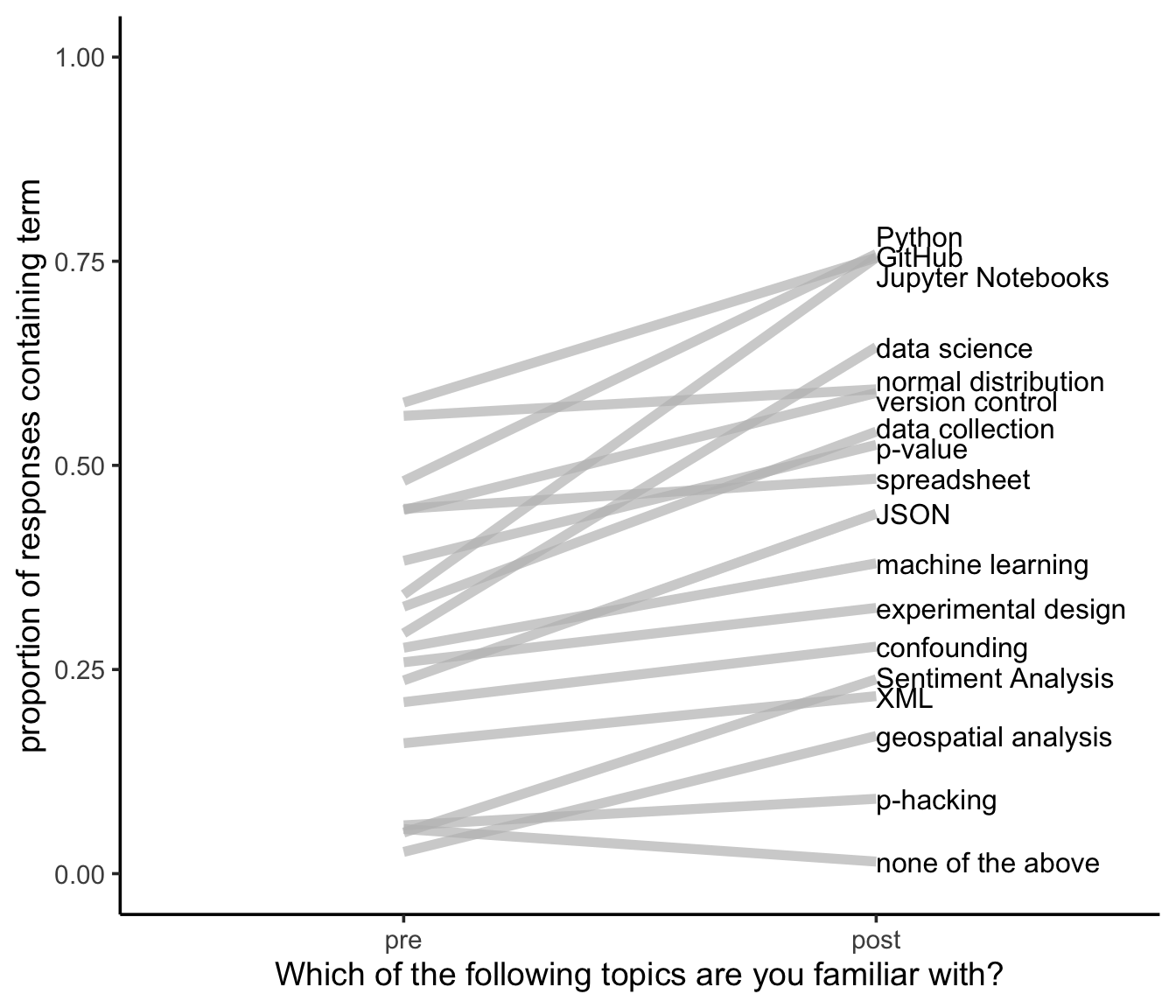
This plot summarizes the proportion of students saying they were familiar with the term at the beginning of the quarter (pre) and the end of the quarter (post). From my perspective, I’m interested in positive sloping lines - indicating that more students were familiar with the topic at the end of the course than they were at the beginning. The only downward sloping line I wanted to see was in the “none of the above” response.
Negative Control
Now, I did add in two topics to the question that we don’t cover in COGS 108 as negative controls: experimental design and p-hacking.
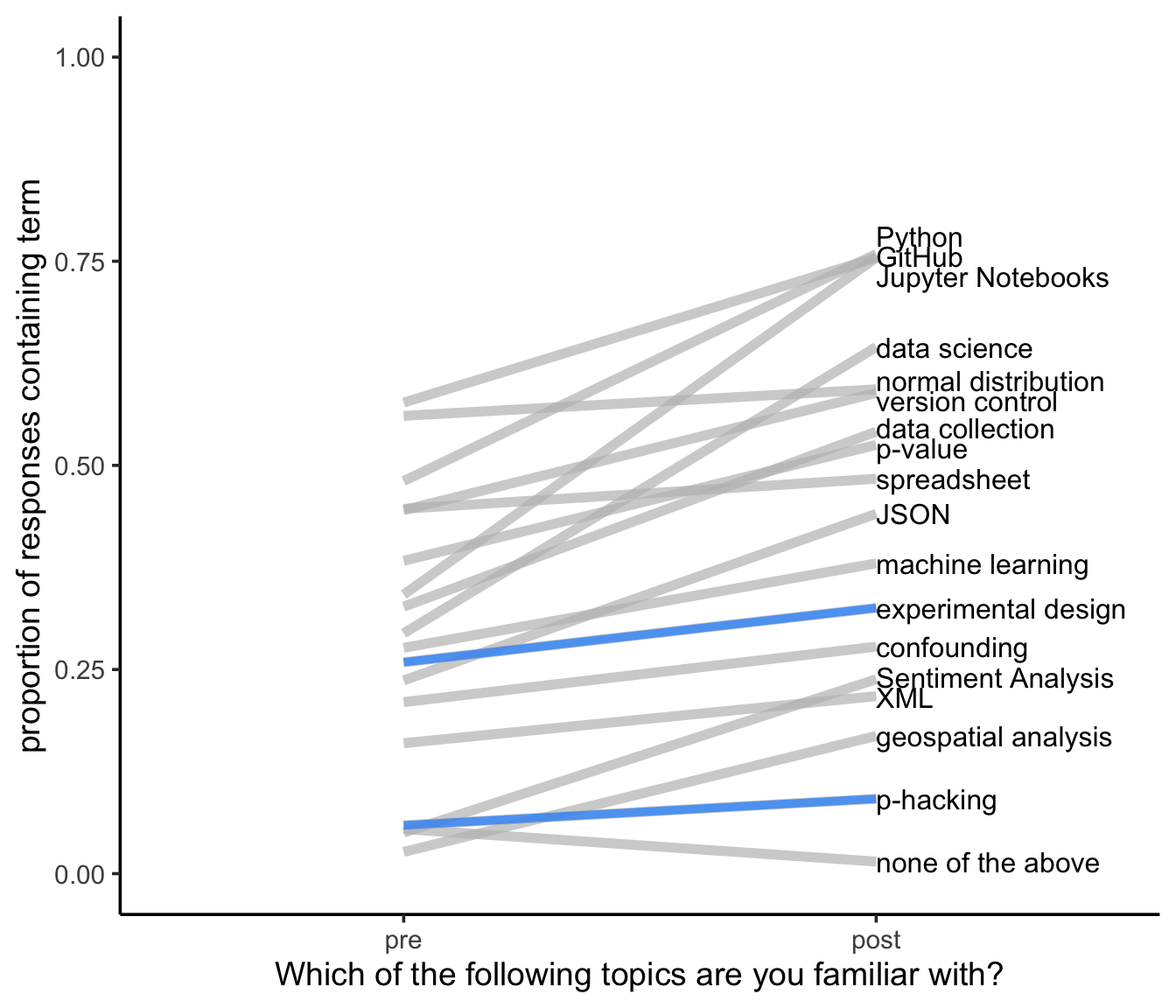
We see that these are pretty flat lines - those are generally well-behaving negative controls. However, that means that anything else with a similarly sloped line are likely things that I need to improve on teaching next time I teach COGS 108. Also, students should know about p-hacking. Time to move that out of the negative control category.
Needs Improvement
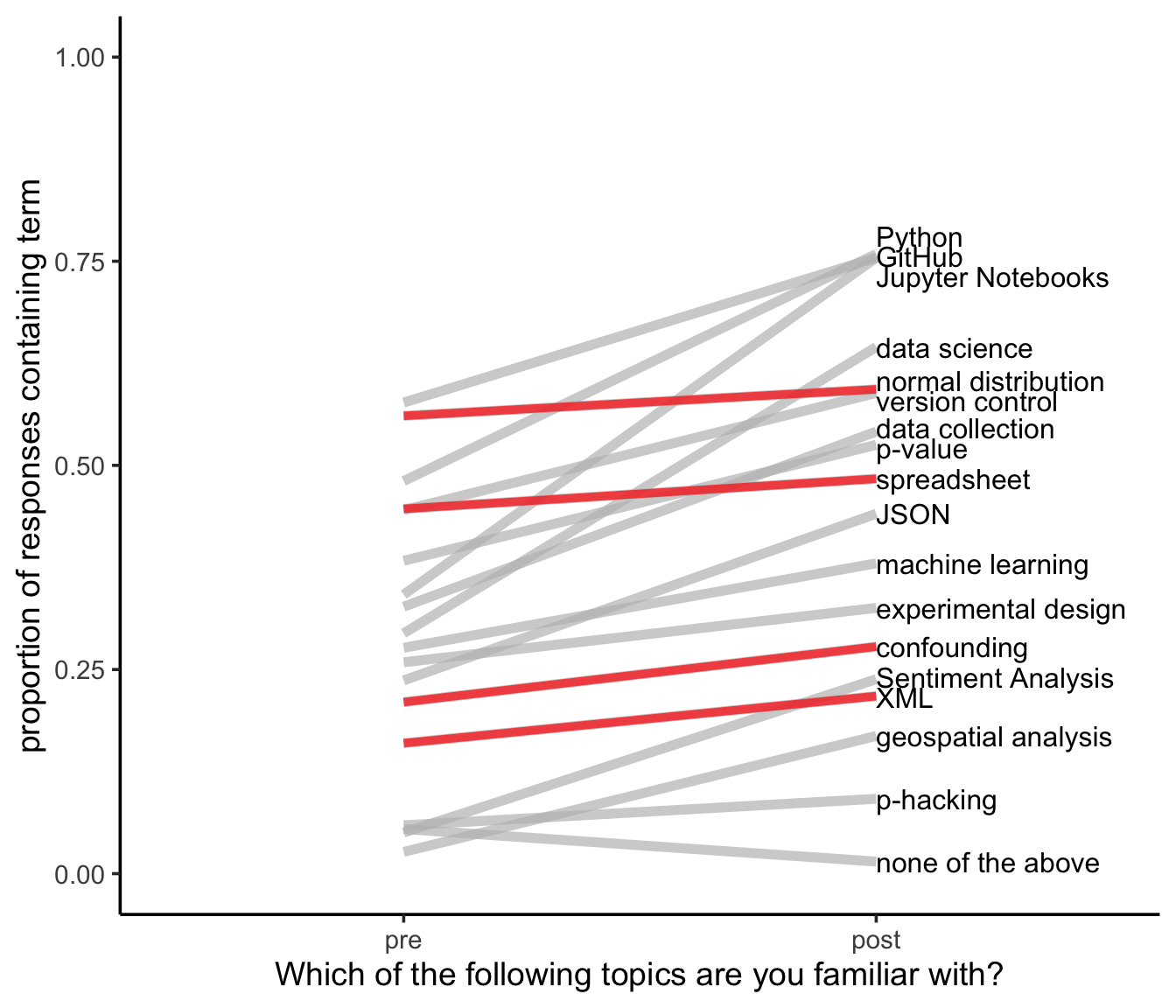
For these topics, the fact that a majority of students come in familiar with Normal distributions is a good thing; however, I definitely want that higher than 60% at the end of class. And, confounding is incredibly important and I’m not getting through to my students it seems. Time to rethink how I approach this topic.
Also, halfway through the quarter I was informed (by awesome high school educators) that high school students are generally unfamiliar with Excel/Google Sheets/spreadsheets. So, this lower proportion of students knowing what a spreadsheet is is now understandable; however, I’ve been teaching from the assumption that my students are familiar with spreadsheets. Time to change that.
Now, as for XML, I mention it briefly. We don’t practice with it a ton. I’d love to see a stronger positive slope…but I’m less worried about that one.
Good News
With that discussed, let’s see where we made the most improvement!
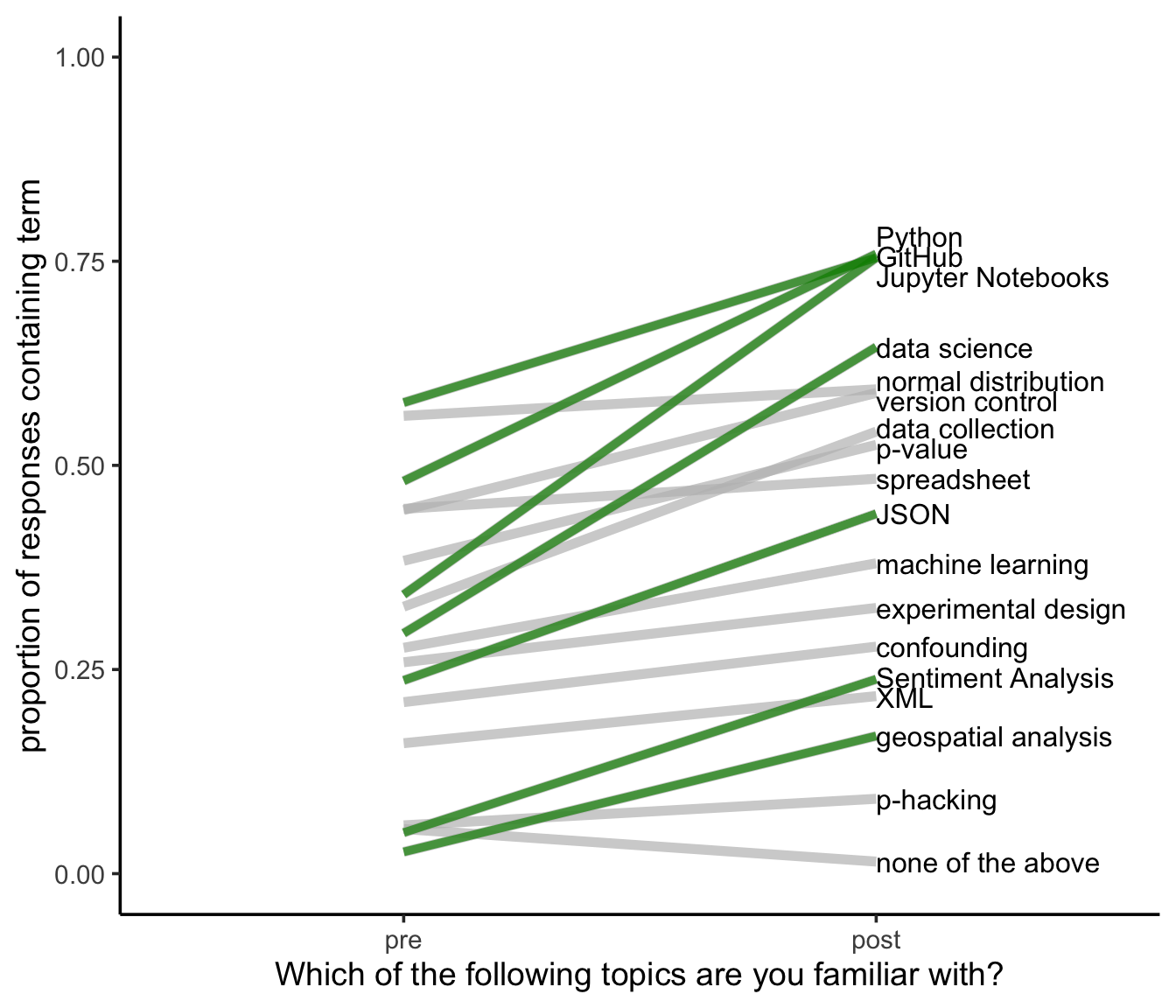
It’s good to see here that students are largely comfortable with Python, GitHub, and Jupyter Notebooks as we use them throughout the class. However, I am curious why this overall proportion isn’t higher. The highest proportion we have is 0.75. I’d love to see this climb toward 100%; however, I’ll note that I didn’t shuffle these options and students could have clicked a single box and moved on. Will change that in the future to get better estimates. This is certainly a conservative estimate, but I’m concerned that the overall proportion isn’t higher.
I’m also happy to see that a large proportion of the class understands sentiment analysis and geospatial analysis better at the end of class as these were topics covered toward the end of the quarter.
Compared to COGS9
COGS 108 is an upper level course, so students are primarily seniors and juniors. The data here encouragingly reflect that students come in more familiar with the topics covered in this course than my students in COGS 9 (an intro-level course) did, where the proportion of responses familiar with the term at the beginning of the class were largely below 0.25.
This suggests that our students are getting familiarity with these concepts before they get to COGS 108, which is great!
Steps for Improvement
I mentioned earlier that there are no exams for this course. I have a hunch that students would get a better mastery of the material if we tested it directly, so I’m considering this in the future.
Additionally, attendance is not required. I collected some data with regards to this that I’ll analyze in a future blog post.
And, for the data directly, I’ll shuffle the order in which the responses are shown to students in the future to hopefully get more accurate data. I’m also going to show the class this blog post…so they know I actually look at and use the data…hopefully encouraging them to answer honestly.
As for teaching, I have a whole bunch of ideas I’m going to try out and I’ll let you all know them in the future as well!